Combining Motion Matching and Orientation Prediction to Animate Avatars for Consumer-Grade VR Devices
Jose Luis Ponton
Haoran Yun
Carlos Andujar
Nuria Pelechano

Abstract
The animation of user avatars plays a crucial role in conveying their pose, gestures, and relative distances to virtual objects
or other users. Consumer-grade VR devices typically include three trackers: the Head Mounted Display (HMD) and
two handheld VR controllers. Since the problem of reconstructing the user pose from such sparse data is ill-defined,
especially for the lower body, the approach adopted by most VR games consists of assuming the body orientation matches
that of the HMD, and applying animation blending and time-warping from a reduced set of animations. Unfortunately, this
approach produces noticeable mismatches between user and avatar movements. In this work we present a new approach to
animate user avatars for current mainstream VR devices. First, we use a neural network to estimate the user’s
body orientation based on the tracking information from the HMD and the hand controllers. Then we use this orientation
together with the velocity and rotation of the HMD to build a feature vector that feeds a Motion Matching algorithm. We built a
MoCap database with animations of VR users wearing a HMD and used it to test our approach on both self-avatars and other
users’ avatars. Our results show that our system can provide a large variety of lower body animations while correctly matching
the user orientation, which in turn allows us to represent not only forward movements but also stepping in any direction.


Method
We propose a new method to animate self-avatars using only one HMD and two hand-held controllers. Our system can be divided into three parts:
- Body orientation prediction
- Motion Matching
- Final pose adjustments
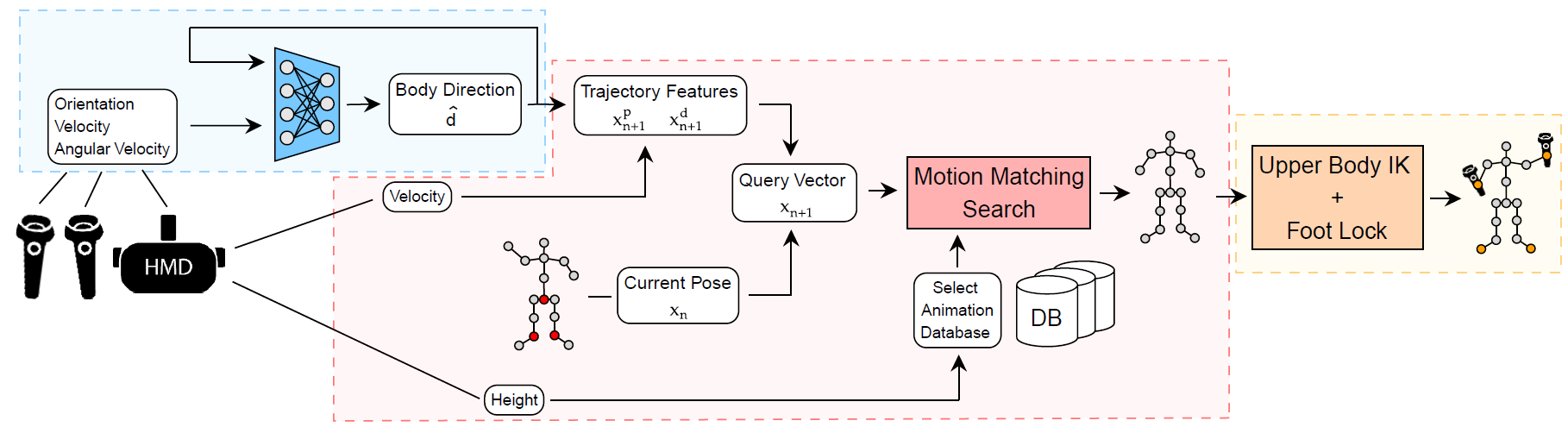
Body Orientation Prediction
Predicting the body orientation is a common problem in applications using full-body avatars with only one HMD and two controllers. Current methods use the HMD's forward direction to orient the whole body, producing mismatches with the actual body orientation. Instead, we trained a lightweight feedforward neural network to predict the body orientation from the rotation, velocity and angular velocity of all three devices.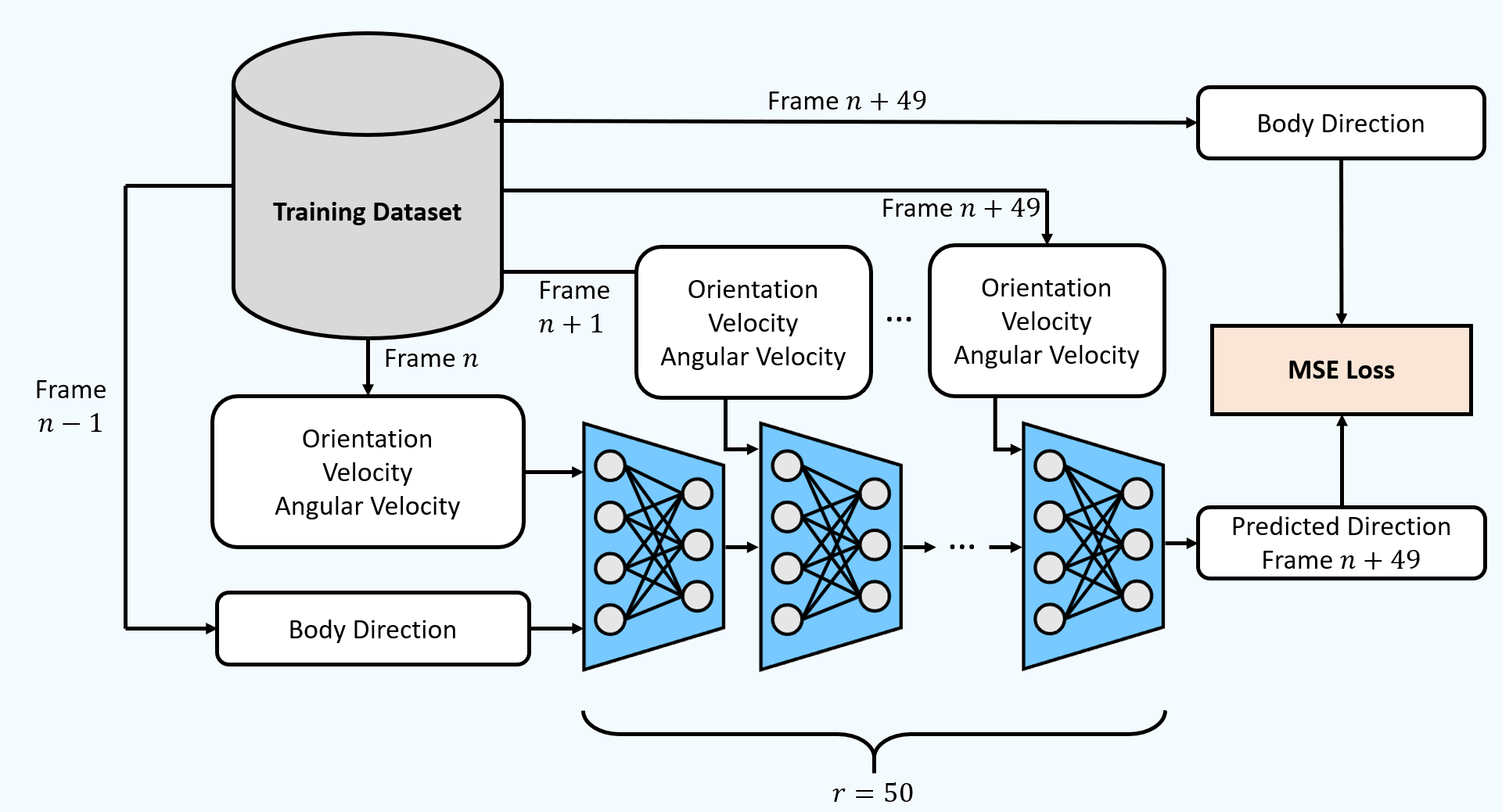
Motion Matching for VR
Motion Matching searches over an animation database for the best match for the current avatar pose and the predicted trajectory. To find the best match, we compute a new database with the main features defining locomotion. A feature vector \( \mathbf{z} \in \mathbb{R}^{27} \) is defined for each pose. This feature vector combines two types of information: the current pose and the trajectory. When comparing feature vectors, the former ensures no significant changes in the pose and thus smooth transitions; the latter drives the animation towards our target trajectory. Feature vectors are defined as follows: \begin{equation*} \mathbf{z} = \left( \mathbf{z^v}, \mathbf{z^l}, \mathbf{z^p}, \mathbf{z^d} \right) \label{eq:z} \end{equation*} where \( \mathbf{z^v}, \mathbf{z^l} \) are the current pose features and \( \mathbf{z^p}, \mathbf{z^d} \) are the trajectory features. More precisely, \( \mathbf{z^v} \in \mathbb{R}^{9} \) are the velocities of the feet and hip joints, \( \mathbf{z^l} \in \mathbb{R}^{6} \) are the positions of the feet joints, \( \mathbf{z^p} \in \mathbb{R}^{6} \) and \( \mathbf{z^d} \in \mathbb{R}^{6} \) are the future 2D positions and 2D orientations of the character \( 0.33 \) , \( 0.66 \) and \( 1.00 \) seconds ahead.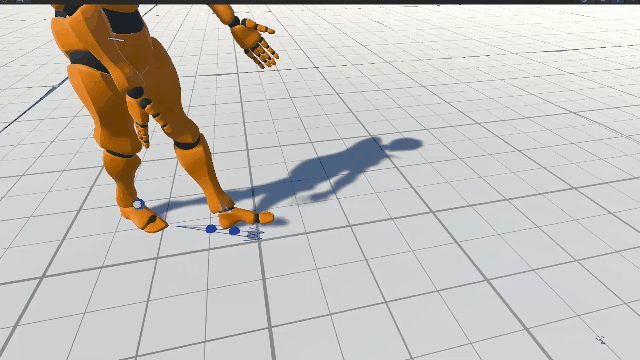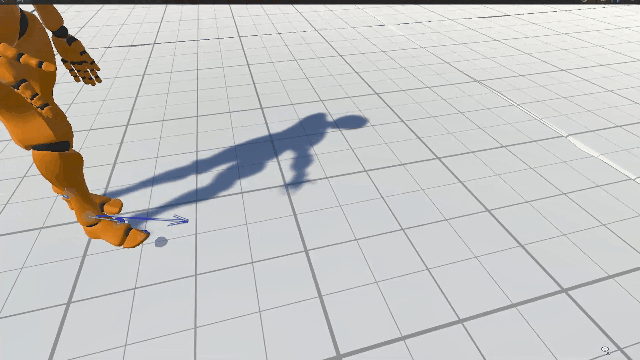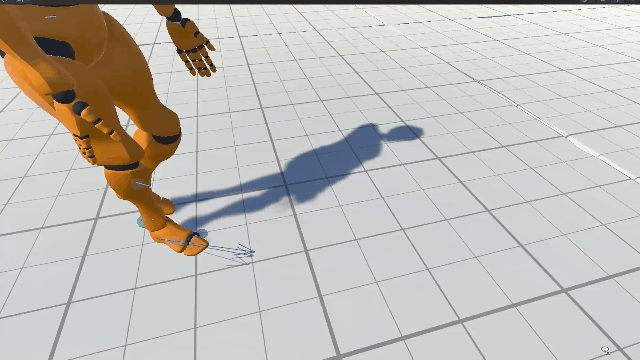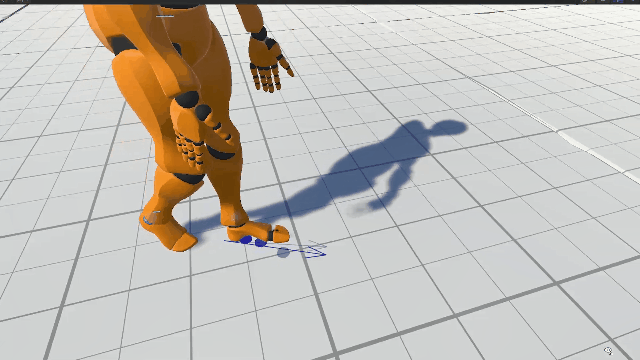
Final pose adjustments
In our work, the upper body is not considered for the Motion Matching algorithm to avoid increasing the dimensionality of the feature vector and focus instead on lower body locomotion, for which no tracking data is available in consumer-grade VR. In order to obtain the upper body pose for the arms, we can use the hand controllers as end effectors for an Inverse Kinematics algorithm. This solution is fast to compute and provides a good solution for the user to interact with the environment in VR.
Overview Video
Citation
@article {ponton2022mmvr,
journal = {Computer Graphics Forum},
title = {{Combining Motion Matching and Orientation Prediction to Animate Avatars for Consumer-Grade VR Devices}},
author = {Ponton, Jose Luis and Yun, Haoran and Andujar, Carlos and Pelechano, Nuria},
year = {2022},
volume = {41},
number = {8},
pages = {107-118},
ISSN = {1467-8659},
DOI = {10.1111/cgf.14628}
}
journal = {Computer Graphics Forum},
title = {{Combining Motion Matching and Orientation Prediction to Animate Avatars for Consumer-Grade VR Devices}},
author = {Ponton, Jose Luis and Yun, Haoran and Andujar, Carlos and Pelechano, Nuria},
year = {2022},
volume = {41},
number = {8},
pages = {107-118},
ISSN = {1467-8659},
DOI = {10.1111/cgf.14628}
}