SparsePoser: Real-time Full-body Motion Reconstruction from Sparse Data
Jose Luis Ponton*,1
Haoran Yun*,1
Andreas Aristidou2,3
Carlos Andujar1
Nuria Pelechano1

Abstract
We introduce SparsePoser, a novel deep learning-based solution for reconstructing a full-body pose from a reduced set of six tracking devices. Our system incorporates a convolutional-based autoencoder that synthesizes high-quality continuous human poses by learning the human motion manifold from motion capture data. Then, we employ a learned IK component, made of multiple lightweight feed-forward neural networks, to adjust the hands and feet towards the corresponding trackers. We extensively evaluate our method on publicly available motion capture datasets and with real-time live demos. We show that our method outperforms state-of-the-art techniques using IMU sensors or 6-DoF tracking devices, and can be used for users with different body dimensions and proportions.
Method
We propose a deep learning-based framework for animating human avatars from a sparse set of input sensors Our system can be divided into two parts:
- Generator is a convolutional-based autoencoder that extracts the main features from the sensors and reconstructs the user poses for a set of contiguous frames.
- Learned IK is a set of feedforward neural networks that adjust the positions of the end-effectors to attain the target points.
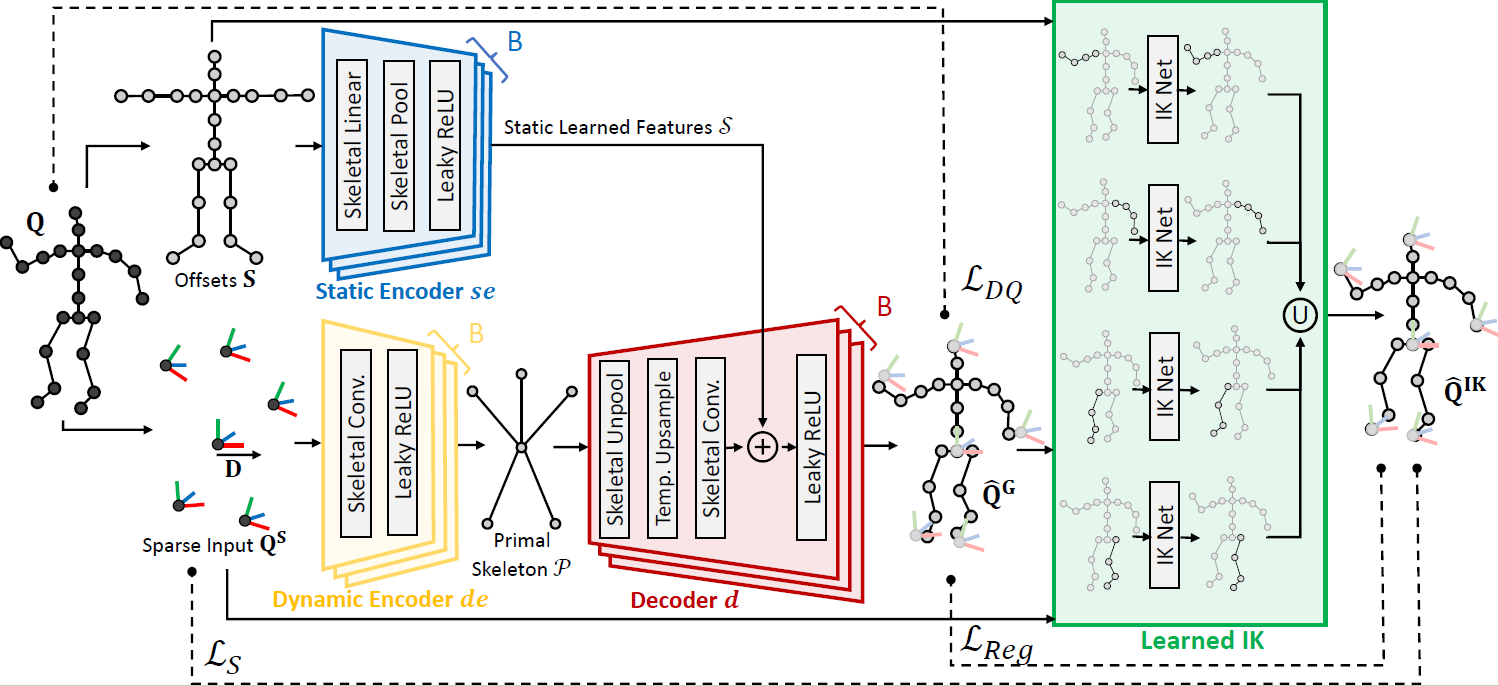
Generator
The generator takes three inputs: \( \mathbf{S} \) (static component, contains the skeleton offsets), \( \mathbf{Q} \) (dynamic component, root space local rotations and translations of all joints), and \( \mathbf{D} \) (displacement component, root displacement between two frames), and produces a full-body pose. It consists of a Static Encoder \( se \), Dynamic Encoder \( de \), and Decoder \( d \). The Static Encoder extracts learned features from \( \mathbf{S} \), while the Dynamic Encoder encodes the primal skeleton using \( \mathbf{D} \) and a subset of \( \mathbf{Q} \). The Decoder reconstructs the pose using the learned features and the primal skeleton. To ensure stable training, dual quaternions and Mean Squared Error (MSE) reconstruction loss are used instead of Forward Kinematics-based (FK) losses.Learned IK
The learned IK stage improves end-effector accuracy in the synthesized human poses by the generator. Feedforward neural networks are trained for each limb to make slight adjustments based on the dynamic and static components, improving pose precision. Two losses, \( \mathcal{L}_{S} \) and \( \mathcal{L}_{Reg} \), ensure accurate end-effectors and maintain pose quality. The final loss is a weighted combination, controlling the tradeoff between accuracy and pose quality.
Overview Video
Citation
@article {ponton2023sparseposer,
author = {Ponton, Jose Luis and Yun, Haoran and Aristidou, Andreas and Andujar, Carlos and Pelechano, Nuria},
title = {SparsePoser: Real-Time Full-Body Motion Reconstruction from Sparse Data},
year = {2023},
issue_date = {February 2024},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {43},
number = {1},
issn = {0730-0301},
url = {https://doi.org/10.1145/3625264},
doi = {10.1145/3625264},
journal = {ACM Trans. Graph.},
month = {oct},
articleno = {5},
numpages = {14}
}
author = {Ponton, Jose Luis and Yun, Haoran and Aristidou, Andreas and Andujar, Carlos and Pelechano, Nuria},
title = {SparsePoser: Real-Time Full-Body Motion Reconstruction from Sparse Data},
year = {2023},
issue_date = {February 2024},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {43},
number = {1},
issn = {0730-0301},
url = {https://doi.org/10.1145/3625264},
doi = {10.1145/3625264},
journal = {ACM Trans. Graph.},
month = {oct},
articleno = {5},
numpages = {14}
}